ML Workflow
Data Preprocessing, Exploratory Data Analysis, Data Representation, ML Modeling, Evaluation, Optimization
ML Workflow
데이터 문제 해결하기 위해 ML을 이용한 데이터 분석 과정을 살펴보면, 데이터 전처리, 탐색적 데이터 분석, 데이터 표현, ML모델링, ML모델 최적화 등 과정을 거쳐 ML모델을 생성한다. 각 데이터 분석 각 단계에 대해 알아보자.

Data Preprocessing
데이터 전처리는 ML 알고리즘에 맞게 데이터를 표현(Data Representation)하기 전에 데이터를 전처리하는 단계로 보통 탐색적 데이터 분석(EDA, Exploratory Data Analysis)과 함께 수행되며, 데이터 유형에 따라 전처리하는 방식이 다르다.

수치(Numerical), 범주(Categorical) 데이터
수치, 범주 데이터는 전처리 단계에서 결측치 처리가 중요하며, 다음 시나리오에 따라 전처리를 수행한다.

Natural Language
자연어 전처리는 기본적으로 토큰화, 정재, 품사부착, 개체명 인식, 불용어 제거 단계로 수행되며 모델에 따라 각 단계를 추가/삭제하여 전처리 한다.

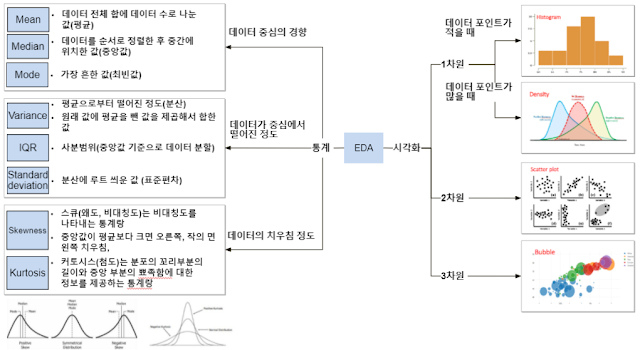
Exploratory Data Analysis
탐색적 데이터 분석는 데이터 전처리와 함께 수행되는 단계로 데이터의 분포나 변수간 관계를 파악하기 위해 통계 기법과 히스토그램, 산점도 등 다양한 시각화 방법을 동원해 데이터의 유의미한 정보를 찾아가는 단계이다. 전처리 대상 선정과 Feature Selection을 수행하는 중요한 단계이다.
Data Representation
데이터 표현은 ML 알고리즘은 컴퓨터가 이해할 수 있는 숫자 형식의 데이터(정수 및 실수)만 가능하기 때문에, 모델링을 진행하기 전에 데이터 형식을 ML 알고리즘에 맞게 데이터를 변형하는 데이터 표현 단계이다.

Word Embedding
단어 임베딩은 단어의 문맥을 학습해서 단어를 표현하는 모델로 문장에 나오는 단어의 순서를 보고 학습하기 때문에 단어의 관계와 유사도를 얻을 수 있다.

ML Modeling
DNN (Deep Neural Network)
인공 신경망은 인간의 뉴런 구조를 본떠 만든 모델이다. 은닉층(Hidden Layer)의 수가 많을 수록 더 복잡한 문제를 해결할 수 있으며, 은닉층 수가 1개면 ANN(Artificial Neural Network), 2개 이상이면 DNN(Deep Neural Network)이라고 한다. DNN은 네트워크를 쌓는 방법에 따라 CNN, RNN 계열 등으로 분류된다.

CNN (Convolutional Neural Network)
이미지 전체를 보는 것이 아니라 부분을 보는 것이 핵심 아이디어이며, 이미지 인식에 효과적인 Features를 스스로 학습하는 딥러닝 알고리즘이다.

Text CNN
CNN은 이미지 인식에 많이 사용되지만, 텍스트 분류하는 작업에도 사용할 수 있다. 텍스트에서 문자의 지역 정보를 보존함으로써 단어의 등장 순서를 학습에 반영하는 딥러닝 알고리즘이다.

RNN (Recurrent Neural Network)
기존 신경망은 모든 입력과 출력이 영향을 주지 않고 독립적으로 판단하지만, 실생활 문제(시계열, 자연어, 음성)들은 이전에 발생한 사건이 현재에 영향을 미칠 때가 많다. 이러한 문제를 풀기 위해 나온 것이 RNN 딥러닝 알고리즘이다.

Seq2Seq
Seq2Seq는 LSTM 기반 모형으로 Encoder와Decoder 2개 파트로 이루어진 딥러닝 알고리즘이다. 도메인에서 다른 도메인으로 시퀀스를 변환하는 모형으로 기계번역 혹은 질의응답에 많이 사용한다. Encoder가 문장의 단어와 단어 순서 정보가 담긴 Context Vector를 만들고, Decoder가 Context Vector를 새로운 문장으로 변환한다. Context Vector는 길이가 고정된 벡터이므로 문장이 길어질 경우, Context Vector에 충분한 정보를 담을 수 없어 모델 성능이 저하된다.

Seq2Seq with Attention
Seq2Seq 문제점을 개선하기 위해 Attention Mechanism이 추가된 알고리즘이다. Decoder에서 출력 단어를 예측하는 매 시점 마다, 예측해야 할 단어와 연관 있는 단어를 좀 더 집중(attention)해서 보는 방식으로 동작한다.

SVM (Support Vector Machine)
지도 학습에서 사용되는 방법으로, 주어진 데이터에 대해서 그 데이터를 분리하는 초평명(hyperplane) 중에서, 데이터와 가장 거리가 먼 초평면을 찾는 방법이다.

Random Forest
Decision Tree 알고리즘이 오버피팅 가능성이 높기 때문에 랜덤포레스트가 도입되었다.기계 학습에서의 랜덤 포레스트는 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종으로 훈련 과정에서 구성한 다수의 결정 트리로부터 분류 또는 예측을 출력함으로써 동작한다.

Matrix Factorization
Matrix Factorization 모델을 이용한 추천 알고리즘으로 잠재요인 모델 중 하나이다.

K-Means
K-Means 알고리즘은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다.

Logistic Regression
로지스틱 회귀분석에서 0~1 범위의 확률값을 0 또는 1의 값으로 매핑한다. 임계값을 초과하는 값은 1이 되고 임계값 보다 낮은 값은 0이 된다. 회귀에서 종속변수 예측 범위는 -무한대~ +무한데인데 logistic은 0~1 사이 예측하므로 분류임에도 회귀라고 부른다.

KNN (K-Nearest Neighbors)
예측할 데이터와 가장 인접한 K개 데이터를 선정하고, K개의 데이터가 가장 많이 속한 분류를 선택한다. 보통 K는 홀수를 많이 사용한다.학습하는 것이 아니면 거리 기반 예측으로 분류 회귀 둘다 사용 가능하다.

Model Evaluation & Model Optimization
Model Evaluation
모델평가에서 학습오차(Training Error)는 모델이 복잡해질 수록 작아지지만, 과적합(Overfitting)될 수 있다. 그러므로, 예측오차(Testing Error)를 최소화하는 학습 모델을 선정하는 것이 중요하다. 예측 오차를 평가하는 방법은 Hold-out Test, k-fold CV 알고리즘 등이 있다.
데이터세트 분리
Hold-out TestDataset를 Training data와 Test data로 나누고 Training data를 이용하여 모델을 fit한 후, fit한 모델을 Test data로 predict하고 predict 결과를 평가한다.
K-fold Cross Validation K-fold CV 알고리즘은 데이터를 k개 set로 분할하고 각 j에 대해 j번째 set을 제외한 나머지를 set을 Training data로 이용하여 모델을 fit한 후, j번째 set을 Test data를 이용하여 예측오차를 구한다. k개의 예측오차의 평균을 활용하여 최적의 모델을 선정한다.
모델의 평가지표
연속형 값을 예측하는 경우는 MSE, MAE, MAPE 등이 평가지표이며, 범주형 값은 Accuracy, Precision, Recall, F-measure 등이 평가지표이다.\
Model Optimization
개발의 마지막 단계에서 이미 얻은 ML모델을 개선하기 위해, 반복 실험을 통해 하이퍼 파라미터를 찾는 과정이다. 이 과정을 자동화한 AutoML 도구를 사용하면 시간 비용을 아낄 수 있다.

Last updated